程序裸奔在服务器,没有经过任何的处理(至于怎么处理,这里先卖个关子,待会儿给大家慢慢道来......),当大流量来临后,会发生什么呢?

图片来自 Pexels
关键时刻服务崩溃,损失了一个亿
有程序员说,对程序进行调优?调优能解决问题码?调优肯定可以解决一部分问题,但是调优仅仅可以缓解程序出现问题,并不能消灭问题。
各位试想一下,当系统面临大流量冲击的时候,CPU 被打满了(请参考下图所示):
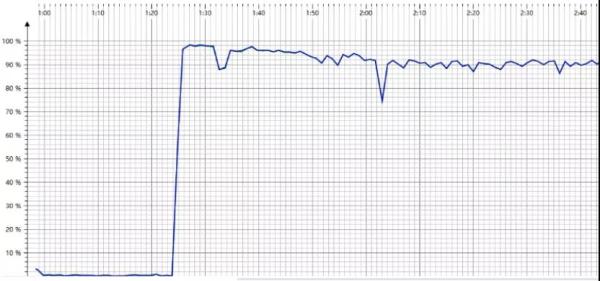
可以发现 CPU 爆满,占比几乎达到 100%,对于系统来说是一个很危险的信号,随时都有可能崩溃掉。
内存被打满了(如下图),这个使用程序都可能出现崩溃:
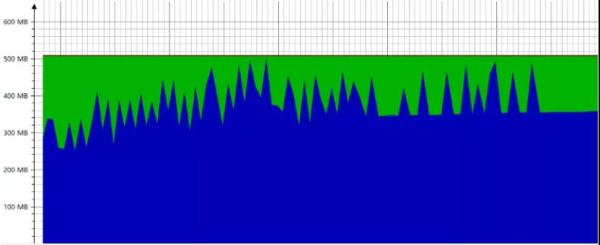
这样的场景就不要调优能解决的了,这涉及到你的可利用的资源就这些,超越了资源使用的极限了,服务肯定扛不住。
可以发现内存平均占用已经超过了 80%,甚至有时候占用达到了接近 100%,这对于系统来说很危险,随时面临崩溃的风险。
那么这个服务该如何解决呢?至于如何解决这些问题,那就是一个非常大的课题,接下来我尽可能的通过有限的篇幅来描述清楚,这个问题该如何解决,如何在高并发,大流量环境下解保证系统平稳,高效的运行。
高并发下系统如何平稳运行
①流量集中,CPU 瘫痪
启动服务:运行 deploy-shop.sh 启动脚本,启动你的服务即可。启动过程中可以查看日志:tail -f t.log,观察是否启动成功。

压力测试:服务启动后,我们可以给定 10w 个样本进行压力测试,来观察服务在压力测试情况下会发生什么问题。
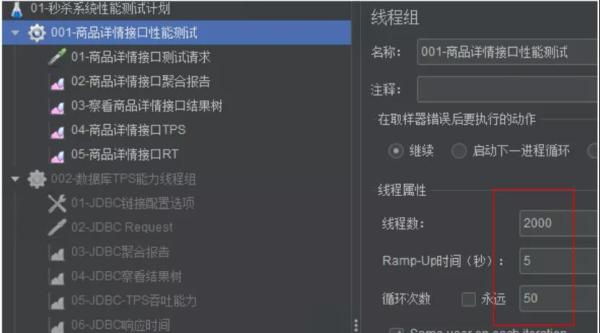
top 指令查询,观察 CPU 指标:
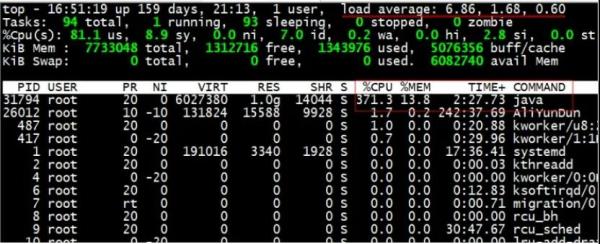
可以看见 load average 最终飙到 10 以上,说明 CPU 已经出现了严重的阻塞现象,如果不能及时解决,线上系统就会出现很严重的问题。

观察 TPS:
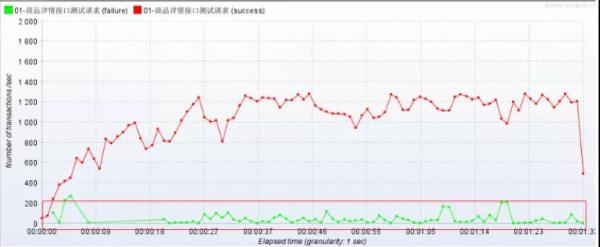
最终结果,就是导致程序程序大量的错误;这些错误还有持续变高的趋势,这对于线上系统来说可以不是一件好事情。
②搞不好,出现 OOM
启动脚本 2:使用脚本:deploy2.sh 启动项目。

这个脚本中限定了项目启动的内存大小为:500M。
- Java 堆溢出 (java.lang.OutofMemoryError:Java heap space),内存溢出 out of memory:是指程序在申请内存时,没有足够的内存空间供其使用,出现 out of memory。
- PermGen space(永久区内部不足)。
- 内存泄露 memory leak,是指程序在申请内存后,无法释放已申请的内存空间,一次内存泄露危害可以忽略,但内存泄露堆积后果很严重,无论多少内存,迟早会被占光。
- StackOverflowError(虚拟机在扩展栈时无法申请到足够的内存空间)。
- 直接崩溃。
压力测试:
监控内存:使用 JProfiler 监控 JVM 内存情况是一种比较好的有效的手段,可以观察内存溢出,内存泄露等等异常情况。
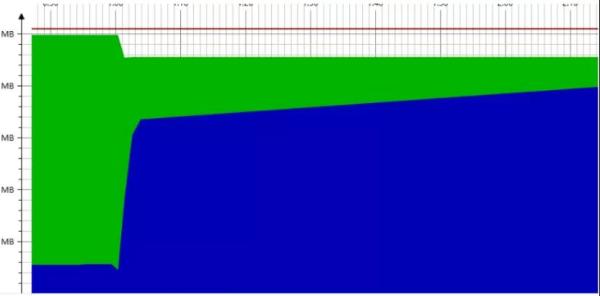
可以发现内存一直处于飙升状态,甚至一度达到了 100%,最后甚至程序直接卡死,走不下去了,程序直接崩溃掉了。
查看日志:
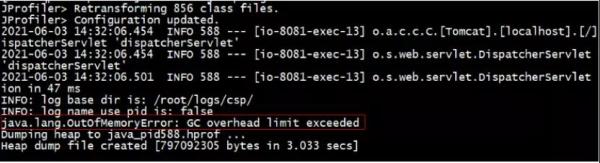
接下来,我们去看一下日志,我们发现直接 OOM 了,甚至程序错误率 100%,直接崩溃。

③服务雪崩效应
在微服务架构中通常会有多个服务层调用,基础服务的故障可能会导致级联故障,进而造成整个系统不可用的情况,这种现象被称为服务雪崩效应。
服务雪崩效应是一种因“服务提供者”的不可用导致“服务消费者”的不可用,并将不可用逐渐放大的过程。
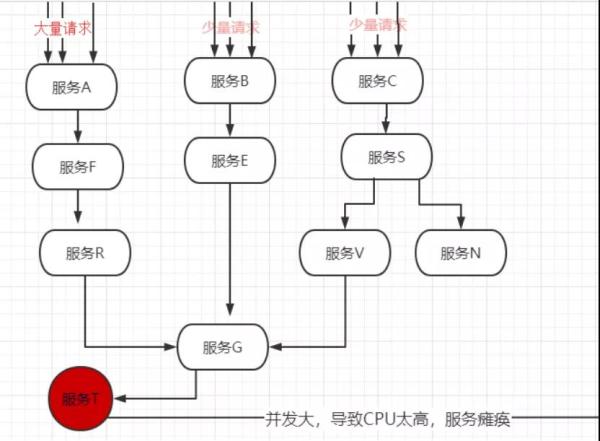
上图所示,如果服务 T 因为高并发宕机,会影响到服务 U,而服务 U 又关联了 3 条线,最终将导致整个系统崩溃,也就是灾难性雪崩效应。
造成的原因:
- 服务提供者不可用(硬件故障,Bug,大量请求)
- 重试加大流量(用户重试不断发送请求,代码逻辑重试)
- 服务调用者不可用(同步等待造成资源耗尽)
有什么好的解决方案呢?
①服务降级
超时降级、资源不足时(线程或信号量)降级,降级后可以配合降级接口返回托底数据。
实现一个 fallback 方法,当请求后端服务出现异常的时候,可以使用 fallback 方法返回的值。
当服务器压力剧增的情况下,根据实际业务情况及流量,对一些服务和页面有策略的不处理或换种简单的方式处理,从而释放服务器资源以保证核心交易正常运作或高效运作。
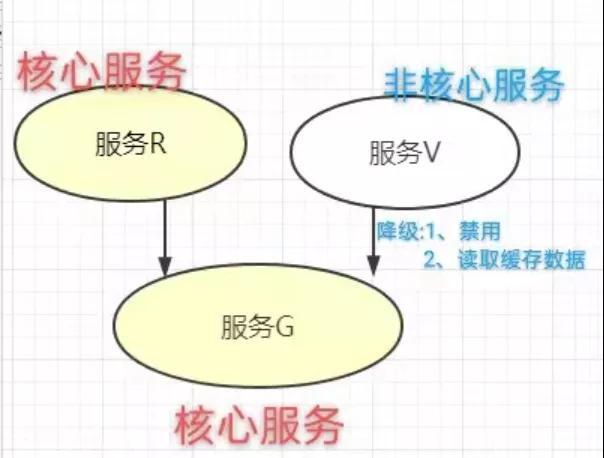
某电商网站在搞活动时,活动期间压力太大,如果再进行下去,整个系统有可能挂掉,这个时候可以释放掉一些资源,将一些不那么重要的服务采取降级措施,比如登录、注册。
登录服务停掉之后就不会有更多的用户抢购,同时释放了一些资源,登录、注册服务就算停掉了也不影响商品抢购。
降级策略:当触发服务降级后,新的交易再次到达时,我们该如何来处理这些请求呢?
从微服务架构全局的视角来看,我们通常有以下是几种常用的降级处理方案:
- 页面降级:可视化界面禁用点击按钮、调整静态页面。
- 延迟服务:如定时任务延迟处理、消息入 MQ 后延迟处理。
- 写降级:直接禁止相关写操作的服务请求。
- 读降级:直接禁止相关读的服务请求。
- 缓存降级:使用缓存方式来降级部分读频繁的服务接口。